Some time ago I attended the "Optimisation by Design" course from Open Query¹. In it, Arjen teaches how writing better queries and schemas can make your database access much faster (and more reliable). One such way of optimising things is by adding appropriate query hints or flags. These hints are magic strings that control how a server executes a query or how it returns results.
An example of such a hint is SQL_CALC_FOUND_ROWS. You use it in a select query with a LIMIT clause. It instructs the server to select a limited numbers of rows, but also to calculate the total number of rows that would have been returned without the limit clause in place. That total number of rows is stored in a session variable, which can be retrieved via SELECT FOUND_ROWS(); That simply reads the variable and clears it on the server, it doesn't actually have to look at any table or index data, so it's very fast.
This is useful when queries are used to generate pages of data where a user can click a specific page number or click previous/next page. In this case you need the total number of rows to determine how many pages you need to generate links for.
The traditional way is to first run a SELECT COUNT(*) query and then select the rows you want, with LIMIT. If you don't use a WHERE clause in your query, this can be pretty fast on MyISAM, as it has a magic variable that contains the number of rows in a table. On InnoDB however, which is my storage engine of choice, there is no such variable and consequently it's not pretty fast.
Paging Drupal
At DrupalConSF earlier this year I'd floated the idea of making Drupal 7 use SQL_CALC_FOUND_ROWS in its pager queries. These are queries generated specifically to display paginated lists of content and the API to do this is pretty straightforward. To do it I needed to add query hint support to the MySQL driver. When it turned out that PostgreSQL and Oracle also support query hints though, the aim became adding hint support for all database drivers.
That's now done, though only the patch only implements hints on the pager under MySQL at the moment.
One issue keeps cropping up though, a blog by Alexey Kovyrin in 2007 that states SELECT COUNT(*) is faster than using SQL_CALC_FOUND_ROWS. It's all very well to not have a patch accepted if that statement is correct, but in my experience that is in fact not the case. In my experience the stats are in fact the other way around, SQL_CALC_FOUND_ROWS is nearly always faster than SELECT COUNT(*).
To back up my claims I thought I should run some benchmarks.
I picked the Drupal pager query that lists content (nodes) on the content administration page. It selects node IDs from the node table with a WHERE clause which filters by the content language. Or, in plain SQL, what currently happens is:
SELECT COUNT(*) FROM node WHERE language = 'und'; SELECT nid FROM node WHERE language = 'und' LIMIT 0,50;
and what I'd like to happen is:
SELECT SQL_CALC_FOUND_ROWS nid FROM node WHERE language = 'und' LIMIT 0,50; SELECT FOUND_ROWS();
Methodology
I ran two sets of tests. One on a node table with 5,000 rows and one with 200,000 rows. For each of these table sizes I ran a pager with 10, 20, 50, 100 and 200 loops, each time increasing the offset by 50; effectively paging through the table. I ran all these using both MyISAM and InnoDB as the storage engine for the node table and I ran them on two machines. One was my desktop, a dual core Athlon X2 5600 with 4Gb of RAM and the other is a single core Xen virtual machine with 512Mb of RAM.
I was hoping to also run tests with 10,000,000 rows, but the virtual machine did not complete any of the queries. So I ran these on my desktop machine only. Again for 10, 20, 50, 100 and 200 queries per run. First with an offset of 50, then with an offset of 10,000. I restarted the MySQL server between each run. To discount query cache advantages, I ran all tests with the query cache disabled. The script I used is attached at the bottom of this post. The calculated times do include the latency of client/server communication, though all tests ran via the local socket connection.
My desktop runs an OurDelta mysql .5.0.87 (the -d10-ourdelta-sail66) to be exact. The virtual machine runs 5.0.87 (-d10-ourdelta65). Before you complain that not running a vanilla MySQL invalidates the results, I run these because I am able to tweak InnoDB a bit more, so the I/O write load on the virtual machine is somewhat reduced compared to the vanilla MySQL.
Results
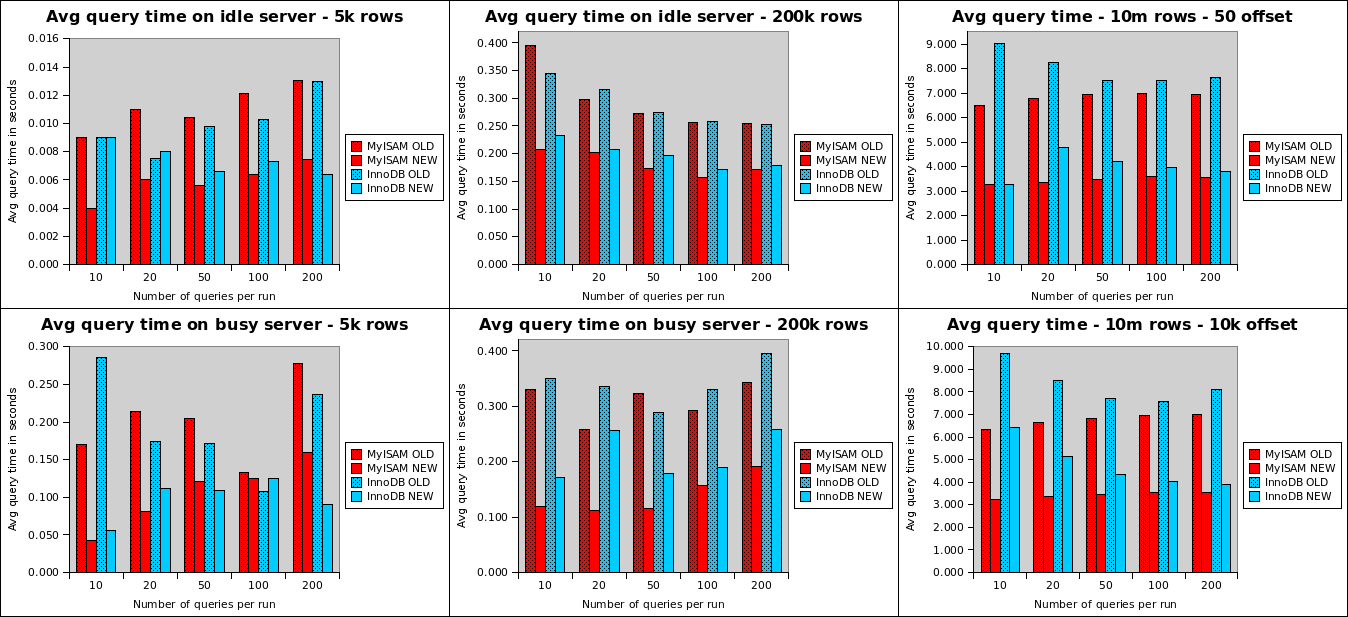
The graphs show that using SQL_CALC_FOUND_ROWS is virtually always faster than running two queries that each need to look at actual data. Even when using MyISAM. As the database gets bigger, the speed advantage of SQL_CALC_FOUND_ROWS increases. At the 10,000,000 row mark, it's consistently about twice as fast.
Also interesting is that InnoDB seems significantly slower than MyISAM on the shorter runs. I say seems, because (especially with the 10,000,000 row table) the delay is caused by InnoDB first loading the table from disk into its buffer pool. In the spreadsheet you can see the first query takes up to 40 seconds, whilst subsequent ones are much faster. The MyISAM data is still in the OS file cache, so it doesn't have that delay on the first query. Because I use innodb_flush_method=O_DIRECT, the InnoDB data is not kept in the OS file cache.
Conclusion
So, it's official. COUNT(*) is dead, long live SQL_CALC_FOUND_ROWS! :-)
I've attached my raw results as a Gnumeric document, so feel free to peruse them. The test script I've used is also attached, so you can re-run the benchmark on your own systems if you wish.
¹ I now work for Open Query as a consultant.
| Attachment | Size |
|---|---|
| 2.55 KB | |
| 136.25 KB | |
| 2.12 KB |
Comments
Another excellent (and
Another excellent (and useful) post!
Faster or not, it doesn't scale.
I read an excellent short guide on this a while back explaining an alternate solution to the often-problematic pagination issue.
Estimation and offset "hints" is key to pagination in this approach.
Pagination example, 10 items per page: message.php (page 1, initial request). Default is to show 10 pages of pagination.
pagination = 10;
limit = 10 * $pagination + 1;
SELECT id, subject, body FROM message ORDER BY id DESC LIMIT $limit;
SELECT id, subject, body FROM message ORDER BY id DESC LIMIT 101;
Example: we have 1 million messages, result will be 101 items in this select!
We can now show 10 clickable pages + "more" because we _know_ there is atleast 11 pages worth of info. We also have primary key hints.
What do we now know from this?
for page 1 -- page_first_id=1; page_last_id=10;
for page 2 -- page_first_id=11; page_last_id=20;
for page 3 -- page_first_id=21; page_last_id=30;
for page 4 -- page_first_id=31; page_last_id=40;
.... assuming there are no gaps in the sequence. But that's ok, this approach will work with gaps as well.
Now we know how to link to the other pages with offset-hints.
for a link to page 4:
message.php?page=4&start=31
resulting SQL:
SELECT id, subject, body FROM message WHERE id >=31 ORDER BY id DESC LIMIT 101;
page=4 here is merely information to know which page the visitor is on, because _his_ page<->offset hints can be different from another visitor's request due to the message table filling up with new messages. Even so, surely when you browse to the "next" page, you don't want to end up reading the same messages on page 5 as you already read on page 4 if there are 10 more messages added to the table while you're busy reading that page.
If the result is less than our LIMIT, or if the result is exactly 100, we know exactly how many pages worth of information there is to display in the paging links.
You could optimize this to select only page limit+1 (LIMIT 11 in our example).
You could then just blindly assume there are another 9 pages worth of info for the client to click... If there isn't, when visitor clicks page 10, he will be revealed the true maximum page# we have.
If there are 58 messages he will end up on page 5 when clicking page 10.
I'm sorry if I went on and on about this but I've seen SQL_CALC_FOUND_ROWS blow up far too many sites. And I'm sorry for any and all errors, I wrote this from the hip and back of my mind :).
Re: Faster or not, it doesn't scale.
Yup, that works fine provided your pagination system is written to work this way. Drupal uses COUNT(*) though. (PATCHES WELCOME!) And in that case SQL_CALC_FOUND_ROWS *is* faster and scales as well as COUNT(*) ... up to 10 million rows anyway :-)
When you're talking about paging through 10 million rows, 50 at a time, you could happily cache the result of FOUND_ROWS() in memcache and simply not bother counting at all for quite a while. The approximate number of total rows wouldn't change much, so it would not actually impact the user.
When you're paging trough 10
When you're paging trough 10 million rows, 50 at a time, thats 200.000 pages - you don't want to have a list of pages thats that long, anyway. (And, would you be using Drupal and its pagination system on such a case?)
Nice article. This is one of those things that I know about, but never seem to actually do.
I do have to say I am supprised that the MyISAM 'old' times change so much between dataset sizes - its magic variable shouldn't be affected by things like that. (Should it?)
Well, it's not that paging
Well, it's not that paging through 10 million rows is common, not even on Drupal, but I need a way to get enough data rows to minimise random noise in the average query time :-)
The thing with the MyISAM magic variable is that the query I run contains a WHERE clause, so it can't be used in this case. On the 10m row run I think I also hit the limit of available RAM on my machine; so the index and the data no longer both fit into the OS file cache, which would've made I/O a factor.
I guess that in theory the same should've been the case for InnODB, though.
At the end of the day, you can (nearly) always make MySQL faster by throwing more hardware at it, but for many Drupal users at least that's not necessarily an option. The large sites will mostly have properly configured dedicated SQL servers, but the smaller sites likely don't.
post EXPLAINs, real performed
post EXPLAINs, real performed queries for both cases and table schema, please.
Hmm, I thought I'd attached
Hmm, I thought I'd attached the script and results file. Now done, as well as the schema.
So, yes, the query in
So, yes, the query in question is using a non-indexed field in its WHERE clause. I did rerun the 10m row test after adding an index and although I no longer get clearcut better results for the SQL_CALC_FOUND_ROWS method, I also don't see it being significantly slower.
Add new comment